今天來分享我在資料職涯行走多年的數據驅動行銷科技的生態系,這其實有很多面向可以延伸,僅以我的職涯經驗為主!這次先以分群和推薦系統為主軸來描述:
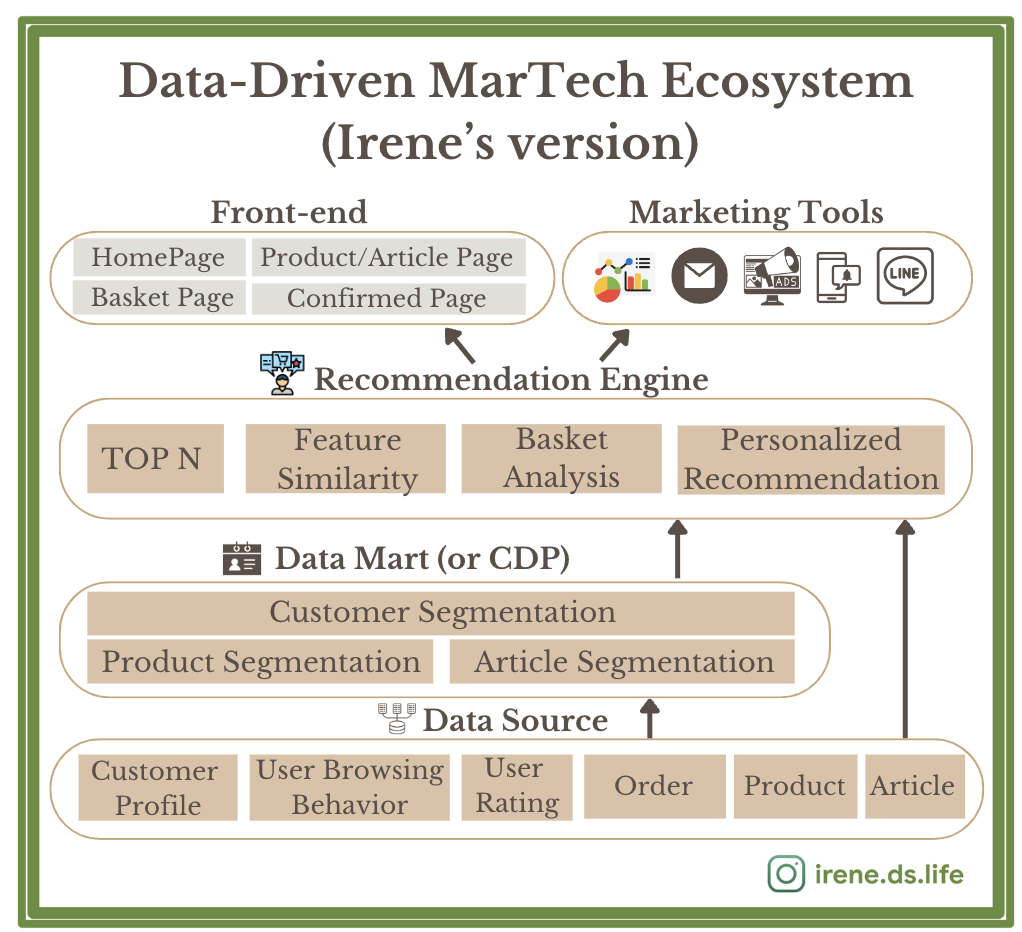
這張簡易的架構圖是我在工作多年後,以不看教科書的前提下,靠著實務經驗畫出來的,它幫助我在資料江湖中行走了好多年,尤其會用在過去在顧問公司時對客戶的提案上。就讓我由架構圖的下方至上方跟你們分享:
ㄧ、資料來源 (Data Source)
前期
一般來說,企業都會有訂單 (Order) 數據和會員數據 (Cusomer Profile)、也會留下一些商品 (Product) 的名稱與描述數據,這些都可以幫助企業做基礎的 CRM 分析,了解帶來最大銷售額的產品會是什麼、會員會是誰。
中後期
接著為了迎接數位化的時代,企業發現使用者開始在網站與 APP 上留下各種行為足跡,讓企業接觸到消費者的歷程變得更長,且更有跡可循。因此使用者瀏覽軌跡 (User Browsing Behavior) 數據變得非常重要,企業開始知道要追蹤這類的數據源,這也是推薦系統開始能蓬勃發展的契機,因為有了這些行為軌跡數據,演算法就能大量使用,能用各種角度解析 「客戶到底喜歡什麼」的神秘面紗。
而這裡的使用者評分 (User Rating) 數據,是指用戶對於商品的感受而給予評分,就像我們現在常常會在 Google Map 上評論商家的心得並給予星等一樣,這類的數據如果能搜集起來會非常有幫助,我們會更知道要優先推薦什麼給這些使用者。
二、資料市集 (Data Mart (or CDP))
這裡想要跟大家分享一個概念,通常資料來源會被存在資料倉儲/資料湖中,它們會是比較原始的數據 (Raw Data) ,我們會需要把這些 Raw Data 經過整理後讓它們變得更有商業意義,這時就會出現一個概念叫做資料市集 (Data Mart),大家常常在說的商品標籤或是客戶標籤也會是這一個階段的產物。
建立這一層級的數據能夠讓系統運算更有效率、減少運算資源的浪費,且在此階段通常也能直接整合到 BI 的服務中,就可以讓行銷人員透過 BI 工具做各種自助式的視覺化報表了。
這邊我提到 CDP 這個詞僅代表客戶標籤,往往外面的廠商都把 CDP 做得太廣了,會直接包山包海連同資料源、演算法和行銷自動化一起解決,但真正需要包山包海的公司其實有限,對於我在職涯中經歷過的大型和中型公司,大部分比較需要的會是客戶標籤數據的加值,通常其他的功能都可能已經被分散到其他廠商的服務,或是自己早已建置完成。
三、推薦系統 (Recommendation Engine)
推薦系統包含多種算法類型,僅先舉比較常見的分享給大家:
(1) 熱門商品(新商品)推薦 (TOP N)
通常在網站上會有推薦的結果是根據商品的銷售熱門程度來決定商品推薦的排序,另外行銷人員通常也會有一些推廣新品的 KPI ,所以也會放「新品推薦」的推薦版位。這兩種通常僅需要基礎的統計且單純的資料源就能計算完成,都先被我定義成是 Top N 推薦方法。
(2) 物品相似度推薦 (Feature Similarity/Content Similarity)
舉一個我作為講師萬年舉例的例子:我在第一次登入 Netflix 時,是沒有被搜集觀影紀錄的,但 Netflix 很聰明,在我註冊的當下就有給我一個類型非常多元的片單,問我喜歡的影集類型(這就是解決冷啟動的方法之一),我選了多部電影,其中一部是全面啟動 (Inception),而有趣的事情發生了,當我進到服務首頁後,它就推薦給我 <隔離島> 這部電影。其實邏輯不難,這就是透過物品相似度計算而來的,因為這兩部電影的主角都是同一個演員、電影的類型都是比較懸疑類的,因此 Netflix 就透過物品相似推薦當時還不知道歡影紀錄的我隔離島這部電影。
(3) 購物籃推薦 (Basket Analysis)
「為什麼啤酒跟尿布會被放在一起推薦給大眾?」這句話是行銷同事可能很常會聽到的老故事(雖然據說它不是真的),無論如何這都在表達一個很棒的精神,「當兩個商品常常出現在同一個訂單 (購物車)中」他們就具有一定程度的關聯性。舉一個我生活的例子,我曾經在 Pinkoi 購買過品酒相關的課程,我想 Pinkoi 大概發現品酒課程和咖啡製作體驗課程很常會被同一個人購買或瀏覽,因此就推薦咖啡製作體驗課程給我。
(4) 個人化推薦 (Personalized Recommendation)
「你有發現過有時候同一個畫面,你看到的推薦結果跟你朋友看到的不一樣嗎?」這就是個人化推薦厲害的地方,因為通常這種推薦方法會根據使用者瀏覽軌跡的數據和使用者評分的數據而近一步計算,所以才能玩出個人化推薦的招數。這種推薦方法通常又分成以下兩種:
* Item Based Collabrative Filtering :當 A 和 B 商品很常被同一個人購買,系統已經發現了這兩個商品的關聯性,當你某天看了 A 商品,系統就可能會自動推薦 B 商品給你 。
* User Based Collabrative Filtering :系統已經根據歷史軌跡發現你和小真兩個人的購物或瀏覽行為很像,所以當你把某個商品放入購物車的時後,系統會自動推薦出小真也曾購買的商品給你,猜測你應該也會喜歡。
四、前端呈現 (Front-end)
這裡指的是前面的分析可能會呈現在服務網站頁面上的位置,推薦版位通常會被分配在服務的首頁、產品 or 文章頁、購物車頁面、結帳頁面等等,這也是我們能夠到處看到推薦系統足跡的原因,而每一種頁面類型所代表的客戶意圖都不一樣,所以當然推薦算法就應該要更符合這些不同頁面位置來分析客戶意圖啦。
五、行銷工具 (Marketing Tools)
另外一種會接觸到客戶的地方會是一些行銷工具,例如 Email 、APP Push、廣告系統、Line 渠道等,這類型的行銷工具因為都會被要求計算更精準的商業指標,例如:轉換的所需成本、轉換率、點擊率等,所以會被要求盡量不要廣發名單,而是要知道客戶大概的輪廓之後,篩選需要的客戶再接觸他們,這也能避免消費者對於過多的訊息而對品牌感到疲勞。
這裡我還有放一個 icon 是指 BI 報表,通常會是使用 Excel/Google Sheet、商業智慧工具 (Tableau/PowerBI/Data Studio),用來輔助商業決策。行銷決策同仁能透過這些工具自主的拉取各種分析結果,有可能會因此做成各種向上管理報告的素材。
以上分享給大家,這簡易的架構圖一定會有我遺漏的地方,畢竟只是我人生經歷碰過的,不代表所有產業的問題,但至少這基礎的框架已經讓我能用在很多企業中,希望對大家有些幫助喔!歡迎收藏 IG 同篇貼文!